4.2 Tidyverse
Muitas pessoas tentam definir o que é ciência de dados no mercado e na academia. O problema é que esse termo pode ser descrito de várias formas distintas, seja pela formação específica da pessoa que define ou da pessoa à qual ela se comunica. Por isso, a definição de ciência de dados é, de certa forma, vazia.
No entanto, é possível definir como se faz ciência de dados. Ou seja, independentemente da definição do termo, o que temos de fazer na prática em projetos reais é algo bastante conhecido.
O “como faz” é definido através do Ciclo da Ciência de Dados, descrito na Figura 4.1. Primeiro, os dados brutos são coletados de fontes públicas, como arquivos Excel, portais de dados abertos ou bases de dados internos da companhia. Em seguida, os dados são arrumados, para mitigar problemas de padronização de nomes, obtenção das variáveis de interesse e exclusão de casos que estão fora do escopo de análise, produzindo o que se define como base de dados analítica. A base analítica é então transformada para produzir as tabelas e gráficos e, quando necessário, são utilizadas como insumo para o ajuste de modelos estatísticos. Finalmente, os resultados obtidos são comunicados através de uma série de ferramentas, como relatórios, dashboards interativos, indicadores ou Application Programming Interfaces (API) para automação.

Figura 4.1: O Ciclo da Ciência de Dados.
O {tidyverse} é um pacote guarda-chuva que consolida uma série de ferramentas que fazem parte do ciclo da ciência de dados. Fazem parte do {tidyverse} os pacotes {ggplot2}, {dplyr}, {tidyr}, {purrr}, {readr}, entre muitos outros, como é possível observar na Figura 4.2. Veremos as características principais desses pacotes nas próximas Seções.
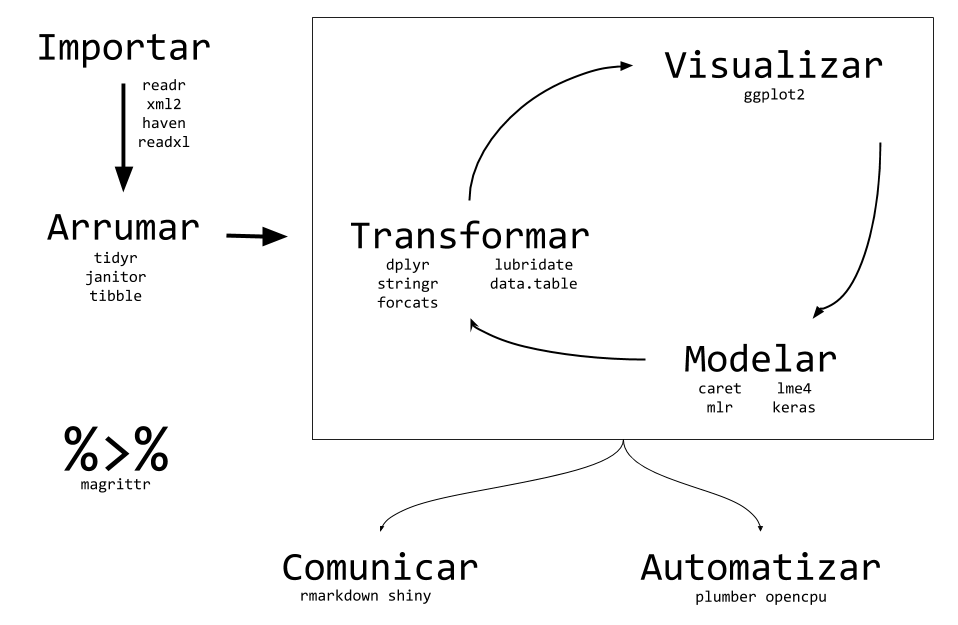
Figura 4.2: A implementação do Ciclo da Ciência de Dados, através do tidyverse. Pela definição estrita do tidyverse, na imagem não fazem parte do tidyverse os pacotes janitor, data.table e os pacotes descritos nas partes de modelagem, comunicação e automatização. No entanto, a maioria desses pacotes também seguem os princípios tidy e podem ser usados em conjunto com o tidyverse sem grandes dificuldades.
O {tidyverse} traz consigo o manifesto tidy. Trata-se de um documento que formaliza uma série de princípios que norteiam o desenvolvimento do tidyverse. Como os pacotes do {tidyverse} compartilham os mesmos princípios, podem ser utilizados naturalmente em conjunto.
Pode-se dizer que existe uma linguagem R antes e outra depois do {tidyverse}. A linguagem mudou muito, a comunidade abraçou o uso desses princípios e criou centenas de novos pacotes que conversam uns com os outros dessa forma.10
Os princípios fundamentais do tidyverse são:
- Reutilizar estruturas de dados existentes.
- Organizar funções simples usando o pipe (Seção 6).
- Aderir à programação funcional (Seção 10).
- Projetado para ser usado por seres humanos.
No texto do manifesto tidy cada um dos lemas é descrito de forma detalhada. No nosso blog, selecionamos os aspectos que achamos mais importante de cada um deles.

Na prática, carregar o {tidyverse} é o mesmo que carregar os seguintes pacotes:
{tibble}para data frames repaginados;{readr}para importarmos bases para o R;{tidyr}e{dplyr}para arrumação e manipulação de dados;{stringr}para trabalharmos com textos;{forcats}para trabalharmos com fatores;{ggplot2}para gráficos;{purrr}para programação funcional.
Embora o {tidyverse} instale diversos outros pacotes, apenas esses são carrregados. Dificilmente fazemos uma análise de dados em que não precisamos usá-los. Falaremos com mais detalhes de todos eles neste livro.
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──## ✔ ggplot2 3.3.6 ✔ purrr 0.3.4
## ✔ tibble 3.1.7 ✔ dplyr 1.0.9
## ✔ tidyr 1.2.0 ✔ stringr 1.4.0
## ✔ readr 2.1.2 ✔ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()Mensagens de conflito quando carregamos o {tidyverse} ou qualquer outro pacote significam que funções anteriormente carregadas foram mascaradas por novas funções. No exemplo acima, as funções filter() e lag() do pacote stats foram substituídas na sessão pelas funções filter() e lag() do pacote dplyr. Nesse caso, se quiséssemos usar as funções do pacote stats após carregar o {tidyverse}, precisaríamos rodar stats::filter() e stats::lag().
Se você quiser descarregar um pacote, reinicie a sua sessão em Session > Restart R ou use a função detach() como no exemplo abaixo.
detach("package:tidyverse", unload = TRUE)Usar a filosofia tidy não é a única forma de fazer pacotes do R. Existem muitos pacotes excelentes que não utilizam essa filosofia. O próprio manifesto diz “O contrário de tidyverse não é o messyverse, e sim muitos outros universos de pacotes interconectados.”↩︎