7.2 O pacote dplyr
O dplyr é o pacote mais útil para realizar transformação de dados, aliando simplicidade e eficiência de uma forma elegante. Os scripts em R que fazem uso inteligente dos verbos dplyr e as facilidades do operador pipe tendem a ficar mais legíveis e organizados, sem perder velocidade de execução.
As principais funções do dplyr são:
select()- seleciona colunasarrange()- ordena a basefilter()- filtra linhasmutate()- cria/modifica colunasgroup_by()- agrupa a basesummarise()- sumariza a base
Todas essas funções seguem as mesmas características:
- O input é sempre uma
tibblee o output é sempre umatibble. - Colocamos a
tibbleno primeiro argumento e o que queremos fazer nos outros argumentos. - A utilização é facilitada com o emprego do operador
%>%.
As principais vantagens de se usar o dplyr em detrimento das funções do R base são:
- Manipular dados se torna uma tarefa muito mais simples.
- O código fica mais intuitivo de ser escrito e mais simples de ser lido.
- O pacote
dplyrutilizaCeC++por trás da maioria das funções, o que geralmente torna o código mais rápido. - É possível trabalhar com diferentes fontes de dados, como bases relacionais (SQL) e
data.table.
Se você ainda não tiver o dplyr instalado, rode o código abaixo.
install.packages("dplyr")
library(dplyr)Neste capítulo, vamos trabalhar com uma base de filmes do IMDB. Essa base pode ser baixada clicando aqui.
Assim, utilizaremos o objeto imdb para acessar os dados.
imdb <- readr::read_rds("imdb.rds")
imdb## # A tibble: 11,340 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0037931 Murde… 1945 1945-06-23 Comedy… 91 USA Engli… NA
## 3 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
## 4 tt0033945 Never… 1941 1947-05-02 Comedy… 71 USA Engli… NA
## 5 tt0372122 Adam … 2005 2007-05-17 Comedy… 99 USA Engli… NA
## 6 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
## 7 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 8 tt0494652 Welco… 2008 2008-02-08 Comedy… 104 USA Engli… 35000000
## 9 tt0094006 Some … 1987 1988-01-13 Drama,… 95 USA Engli… NA
## 10 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
## # … with 11,330 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>Agora, vamos avaliar com mais detalhes as principais funções do pacote dplyr.
7.2.1 Selecionando colunas
Para selecionar colunas, utilizamos a função select().
O primeiro argumento da função é a base de dados e os demais argumentos são os nomes das colunas que você gostaria de selecionar. Repare que você não precisa colocar o nome da coluna entre aspas.
select(imdb, titulo)## # A tibble: 11,340 × 1
## titulo
## <chr>
## 1 Broadcast News
## 2 Murder, He Says
## 3 Me, Myself & Irene
## 4 Never Give a Sucker an Even Break
## 5 Adam & Steve
## 6 Henry Gamble's Birthday Party
## 7 No Way Out
## 8 Welcome Home, Roscoe Jenkins
## 9 Some Kind of Wonderful
## 10 The Family That Preys
## # … with 11,330 more rowsVocê também pode selecionar várias colunas.
select(imdb, titulo, ano, orcamento)## # A tibble: 11,340 × 3
## titulo ano orcamento
## <chr> <dbl> <dbl>
## 1 Broadcast News 1987 20000000
## 2 Murder, He Says 1945 NA
## 3 Me, Myself & Irene 2000 51000000
## 4 Never Give a Sucker an Even Break 1941 NA
## 5 Adam & Steve 2005 NA
## 6 Henry Gamble's Birthday Party 2015 NA
## 7 No Way Out 1987 15000000
## 8 Welcome Home, Roscoe Jenkins 2008 35000000
## 9 Some Kind of Wonderful 1987 NA
## 10 The Family That Preys 2008 NA
## # … with 11,330 more rowsO operador : é muito útil para selecionar colunas consecutivas.
select(imdb, titulo:generos)## # A tibble: 11,340 × 4
## titulo ano data_lancamento generos
## <chr> <dbl> <chr> <chr>
## 1 Broadcast News 1987 1988-04-01 Comedy, Drama, Roman…
## 2 Murder, He Says 1945 1945-06-23 Comedy, Crime, Myste…
## 3 Me, Myself & Irene 2000 2000-09-08 Comedy
## 4 Never Give a Sucker an Even Break 1941 1947-05-02 Comedy, Musical
## 5 Adam & Steve 2005 2007-05-17 Comedy, Drama, Music
## 6 Henry Gamble's Birthday Party 2015 2016-01-08 Drama
## 7 No Way Out 1987 1987-12-11 Action, Crime, Drama
## 8 Welcome Home, Roscoe Jenkins 2008 2008-02-08 Comedy, Romance
## 9 Some Kind of Wonderful 1987 1988-01-13 Drama, Romance
## 10 The Family That Preys 2008 2008-09-12 Drama
## # … with 11,330 more rowsO dplyr possui um conjunto de funções auxiliares muito úteis para seleção de colunas. As principais são:
starts_with(): para colunas que começam com um texto padrãoends_with(): para colunas que terminam com um texto padrãocontains(): para colunas que contêm um texto padrão
Selecionamos a seguir todas as colunas que começam com o texto “num”.
select(imdb, starts_with("num"))## # A tibble: 11,340 × 3
## num_avaliacoes num_criticas_publico num_criticas_critica
## <dbl> <dbl> <dbl>
## 1 26257 142 62
## 2 1639 35 10
## 3 219069 502 161
## 4 2108 35 18
## 5 2953 48 15
## 6 2364 26 14
## 7 34513 125 72
## 8 13315 45 74
## 9 27065 145 55
## 10 6703 52 29
## # … with 11,330 more rowsPara retirar colunas da base, base acrescentar um - antes da seleção.
select(imdb, -ano, -direcao)## # A tibble: 11,340 × 18
## id_filme titulo data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broadcast N… 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0037931 Murder, He … 1945-06-23 Comedy… 91 USA Engli… NA
## 3 tt0183505 Me, Myself … 2000-09-08 Comedy 116 USA Engli… 51000000
## 4 tt0033945 Never Give … 1947-05-02 Comedy… 71 USA Engli… NA
## 5 tt0372122 Adam & Steve 2007-05-17 Comedy… 99 USA Engli… NA
## 6 tt3703836 Henry Gambl… 2016-01-08 Drama 87 USA Engli… NA
## 7 tt0093640 No Way Out 1987-12-11 Action… 114 USA Engli… 15000000
## 8 tt0494652 Welcome Hom… 2008-02-08 Comedy… 104 USA Engli… 35000000
## 9 tt0094006 Some Kind o… 1988-01-13 Drama,… 95 USA Engli… NA
## 10 tt1142798 The Family … 2008-09-12 Drama 111 USA Engli… NA
## # … with 11,330 more rows, and 10 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, roteiro <chr>,
## # producao <chr>, elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
## # num_criticas_critica <dbl>select(imdb, -starts_with("num"))## # A tibble: 11,340 × 17
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0037931 Murde… 1945 1945-06-23 Comedy… 91 USA Engli… NA
## 3 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
## 4 tt0033945 Never… 1941 1947-05-02 Comedy… 71 USA Engli… NA
## 5 tt0372122 Adam … 2005 2007-05-17 Comedy… 99 USA Engli… NA
## 6 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
## 7 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 8 tt0494652 Welco… 2008 2008-02-08 Comedy… 104 USA Engli… 35000000
## 9 tt0094006 Some … 1987 1988-01-13 Drama,… 95 USA Engli… NA
## 10 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
## # … with 11,330 more rows, and 8 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, direcao <chr>, roteiro <chr>,
## # producao <chr>, elenco <chr>, descricao <chr>Exercícios
Utilize a base imdb nos exercícios a seguir.
1. Teste aplicar a função glimpse() do pacote {dplyr} à base imdb. O que ela faz?
2. Crie uma tabela com apenas as colunas titulo, direcao, e orcamento. Salve em um objeto chamado imdb_simples.
3. Selecione apenas as colunas duracao, direcao, descricao e producao usando a função auxiliar contains().
4. Usando a função select() (e suas funções auxiliares), escreva códigos que retornem a base IMDB sem as colunas num_avaliacoes, num_criticas_publico e num_criticas_critica. Escreva todas as soluções diferentes que você conseguir pensar.
7.2.2 Ordenando a base
Para ordenar linhas, utilizamos a função arrange(). O primeiro argumento é a base de dados. Os demais argumentos são as colunas pelas quais queremos ordenar as linhas. No exemplo a seguir, ordenamos as linhas da base por ordem crescente de orçamento.
arrange(imdb, orcamento)## # A tibble: 11,340 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt5345298 Patie… 2016 2016-10-11 Horror 116 USA Icela… 0
## 2 tt7692822 Driven 2019 2019-02-09 Comedy… 90 USA Engli… 0
## 3 tt3748918 To Yo… 2019 2020-03-17 Animat… 91 USA Engli… 1
## 4 tt8196068 Twist… 2018 2018-10-03 Drama,… 89 USA Engli… 3
## 5 tt0772152 Amate… 2006 2006-07-30 Crime,… 71 USA Engli… 45
## 6 tt1260680 Pathf… 2011 2011-01-11 Action… 100 USA Engli… 50
## 7 tt1701224 My Na… 2012 2012-10-19 Crime,… 90 USA Frenc… 300
## 8 tt0054880 Flami… 1963 1963-04-29 Comedy… 45 USA Engli… 300
## 9 tt1980185 Memor… 2012 2014-03-10 Crime,… 70 USA Engli… 300
## 10 tt5009236 King … 2015 2015-03-27 Biogra… 46 USA Engli… 500
## # … with 11,330 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>Também podemos ordenar de forma decrescente usando a função desc().
arrange(imdb, desc(orcamento))## # A tibble: 11,340 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt4154796 Aveng… 2019 2019-04-24 Action… 181 USA Engli… 356000000
## 2 tt4154756 Aveng… 2018 2018-04-25 Action… 149 USA Engli… 321000000
## 3 tt2527336 Star … 2017 2017-12-13 Action… 152 USA Engli… 317000000
## 4 tt0449088 Pirat… 2007 2007-05-23 Action… 169 USA Engli… 300000000
## 5 tt2527338 Star … 2019 2019-12-18 Action… 141 USA Engli… 275000000
## 6 tt3778644 Solo:… 2018 2018-05-23 Action… 135 USA Engli… 275000000
## 7 tt0348150 Super… 2006 2006-09-01 Action… 154 USA Engli… 270000000
## 8 tt0398286 Tangl… 2010 2010-11-26 Animat… 100 USA Engli… 260000000
## 9 tt0413300 Spide… 2007 2007-05-01 Action… 139 USA Engli… 258000000
## 10 tt2975590 Batma… 2016 2016-03-23 Action… 152 USA Engli… 250000000
## # … with 11,330 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>E claro, ordenar segundo duas ou mais colunas.
arrange(imdb, desc(ano), desc(orcamento))## # A tibble: 11,340 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt6587640 Troll… 2020 2020-04-10 Animat… 90 USA Engli… 90000000
## 2 tt7713068 Birds… 2020 2020-02-06 Action… 109 USA Engli… 84500000
## 3 tt5774060 Under… 2020 2020-01-30 Action… 95 USA Engli… 80000000
## 4 tt6820324 Timmy… 2020 2020-03-24 Advent… 99 USA Engli… 45000000
## 5 tt1634106 Blood… 2020 2020-03-27 Action… 109 USA Engli… 45000000
## 6 tt100595… Unhin… 2020 2020-09-24 Action… 90 USA Engli… 33000000
## 7 tt8461224 The T… 2020 2020-08-07 Action… 95 USA Engli… 30000000
## 8 tt103089… Force… 2020 2020-06-30 Action… 91 USA Engli… 23000000
## 9 tt4411584 The S… 2020 2020-07-31 Drama,… 107 USA Engli… 21000000
## 10 tt8244784 The H… 2020 2020-03-24 Action… 90 USA Engli… 14000000
## # … with 11,330 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>7.2.3 O pipe em ação
Na grande maioria dos casos, vamos aplicar mais de uma função de manipulação em uma base para obtermos a tabela que desejamos. Poderíamos, por exemplo, querer uma tabela apenas com o título e ano dos filmes, ordenada de forma crescente de lançamento. Para fazer isso, poderíamos aninhar as funções
arrange(select(imdb, titulo, ano), ano)## # A tibble: 11,340 × 2
## titulo ano
## <chr> <dbl>
## 1 Tillie's Punctured Romance 1914
## 2 Judith of Bethulia 1914
## 3 The Avenging Conscience: or 'Thou Shalt Not Kill' 1914
## 4 The Regeneration 1915
## 5 The Cheat 1915
## 6 The Birth of a Nation 1915
## 7 Intolerance: Love's Struggle Throughout the Ages 1916
## 8 20,000 Leagues Under the Sea 1916
## 9 The Poor Little Rich Girl 1917
## 10 Shoulder Arms 1918
## # … with 11,330 more rowsou criar um objeto intermediário
tab_titulo_ano <- select(imdb, titulo, ano)
arrange(tab_titulo_ano, ano)## # A tibble: 11,340 × 2
## titulo ano
## <chr> <dbl>
## 1 Tillie's Punctured Romance 1914
## 2 Judith of Bethulia 1914
## 3 The Avenging Conscience: or 'Thou Shalt Not Kill' 1914
## 4 The Regeneration 1915
## 5 The Cheat 1915
## 6 The Birth of a Nation 1915
## 7 Intolerance: Love's Struggle Throughout the Ages 1916
## 8 20,000 Leagues Under the Sea 1916
## 9 The Poor Little Rich Girl 1917
## 10 Shoulder Arms 1918
## # … with 11,330 more rowsOs dois códigos funcionam e levam ao mesmo resultado, mas não são muito bons.
A primeira alternativa é ruim de escrever (já que precisamos escrever primeiro a função que roda por último) e de ler (pois é difícil identificar qual argumento pertence a qual função).
A segunda alternativa também é ruim, pois exige a criação de objetos auxiliares. Se quiséssimos aplicar 10 operações na base, precisaríamos criar 9 objetos intermediários.
A solução para aplicar diversas operações de manipulação em uma base de dados é aplicar o operador pipe: %>%.
imdb %>%
select(titulo, ano) %>%
arrange(ano)## # A tibble: 11,340 × 2
## titulo ano
## <chr> <dbl>
## 1 Tillie's Punctured Romance 1914
## 2 Judith of Bethulia 1914
## 3 The Avenging Conscience: or 'Thou Shalt Not Kill' 1914
## 4 The Regeneration 1915
## 5 The Cheat 1915
## 6 The Birth of a Nation 1915
## 7 Intolerance: Love's Struggle Throughout the Ages 1916
## 8 20,000 Leagues Under the Sea 1916
## 9 The Poor Little Rich Girl 1917
## 10 Shoulder Arms 1918
## # … with 11,330 more rowsO que está sendo feito no código com pipe? Da primeira para a segunda linha, estamos aplicando a função select() à base imdb. Da segunda para a terceira, estamos aplicando a função arrange() à base resultante da função select().
O resultado desse código é idêntico às tentativas sem pipe, com a vantagem de termos escrito o código na ordem em que as funções são aplicadas, de termos um código muito mais legível e de não precisarmos utilizar objetos intermediários.
7.2.4 Filtrando linhas
Para filtrar valores de uma coluna da base, utilizamos a função filter().
imdb %>% filter(nota_imdb > 9)## # A tibble: 5 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt10218912 As I … 2019 2019-12-06 Drama,… 62 USA Engli… 10000
## 2 tt6735740 Love … 2019 2019-06-23 Comedy 100 USA Engli… 3000000
## 3 tt0111161 The S… 1994 1995-02-10 Drama 142 USA Engli… 25000000
## 4 tt0068646 The G… 1972 1972-09-21 Crime,… 175 USA Engli… 6000000
## 5 tt5980638 The T… 2018 2020-06-19 Music,… 96 USA Engli… 90000
## # … with 11 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
## # num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
## # elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
## # num_criticas_critica <dbl>Podemos selecionar apenas as colunas título e nota para visualizarmos as notas:
imdb %>%
filter(nota_imdb > 9) %>%
select(titulo, nota_imdb)## # A tibble: 5 × 2
## titulo nota_imdb
## <chr> <dbl>
## 1 As I Am 9.3
## 2 Love in Kilnerry 9.3
## 3 The Shawshank Redemption 9.3
## 4 The Godfather 9.2
## 5 The Transcendents 9.2Podemos estender o filtro para duas ou mais colunas. Para isso, separamos cada operação por uma vírgula.
imdb %>% filter(ano > 2010, nota_imdb > 8.5)## # A tibble: 8 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt10218912 As I … 2019 2019-12-06 Drama,… 62 USA Engli… 10000
## 2 tt8503618 Hamil… 2020 2020-07-03 Biogra… 160 USA Engli… NA
## 3 tt6735740 Love … 2019 2019-06-23 Comedy 100 USA Engli… 3000000
## 4 tt10765852 Metal… 2019 2019-10-18 Music 150 USA Engli… NA
## 5 tt6019206 Kill … 2011 2011-03-27 Action… 247 USA <NA> NA
## 6 tt8241876 5th B… 2020 2020-06-03 Crime 95 USA Engli… NA
## 7 tt2170667 Wheels 2014 2017-02-01 Drama 115 USA Engli… NA
## 8 tt5980638 The T… 2018 2020-06-19 Music,… 96 USA Engli… 90000
## # … with 11 more variables: receita <dbl>, receita_eua <dbl>, nota_imdb <dbl>,
## # num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>, producao <chr>,
## # elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
## # num_criticas_critica <dbl>Também podemos fazer operações com as colunas da base dentro da função filter. O código abaixo devolve uma tabela apenas com os filmes que lucraram.
imdb %>% filter(receita - orcamento > 0)## # A tibble: 2,541 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
## 3 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 4 tt0494652 Welco… 2008 2008-02-08 Comedy… 104 USA Engli… 35000000
## 5 tt1488555 The C… 2011 2011-12-09 Comedy… 112 USA Engli… 52000000
## 6 tt0090022 Silve… 1985 1986-01-16 Action… 133 USA Engli… 26000000
## 7 tt0120434 Vegas… 1997 1997-02-14 Comedy 93 USA Engli… 25000000
## 8 tt1086772 Blend… 2014 2014-07-02 Comedy… 117 USA Engli… 40000000
## 9 tt0064115 Butch… 1969 1969-09-26 Biogra… 110 USA Engli… 6000000
## 10 tt0441796 Stay … 2006 2006-03-24 Fantas… 85 USA Engli… 7000000
## # … with 2,531 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>Naturalmente, podemos filtrar colunas categóricas. O exemplo abaixo retorna uma tabela apenas com os filmes dirigidos por Quentin Tarantino ou Steven Spielberg.
imdb %>%
filter(direcao %in% c("Quentin Tarantino", "Steven Spielberg"))## # A tibble: 30 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0102057 Hook 1991 1992-03-27 Advent… 142 USA Engli… 70000000
## 2 tt0118607 Amist… 1997 1998-03-13 Biogra… 155 USA Engli… 36000000
## 3 tt0096794 Always 1989 1989-12-22 Drama,… 122 USA Engli… 31000000
## 4 tt0110912 Pulp … 1994 1994-10-28 Crime,… 154 USA Engli… 8000000
## 5 tt0407304 War o… 2005 2005-06-29 Advent… 116 USA Engli… 132000000
## 6 tt0075860 Close… 1977 1978-03-03 Drama,… 138 USA Engli… 20000000
## 7 tt0082971 Raide… 1981 1981-06-12 Action… 115 USA Engli… 18000000
## 8 tt0097576 India… 1989 1989-10-06 Action… 127 USA Engli… 48000000
## 9 tt0362227 The T… 2004 2004-09-03 Comedy… 128 USA Engli… 60000000
## 10 tt0120815 Savin… 1998 1998-10-30 Drama,… 169 USA Engli… 70000000
## # … with 20 more rows, and 11 more variables: receita <dbl>, receita_eua <dbl>,
## # nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>, roteiro <chr>,
## # producao <chr>, elenco <chr>, descricao <chr>, num_criticas_publico <dbl>,
## # num_criticas_critica <dbl>Para filtrar textos sem correspondência exata, podemos utilizar a função auxiliar str_detect() do pacote {stringr}. Ela serve para verificar se cada string de um vetor contém um determinado padrão de texto.
library(stringr)
str_detect(
string = c("a", "aa","abc", "bc", "A", NA),
pattern = "a"
)## [1] TRUE TRUE TRUE FALSE FALSE NAPodemos utilizá-la para filtrar apenas os filmes que contêm o gênero Drama.
# A coluna gêneros apresenta todos os gêneros dos filmes concatenados
imdb$generos[1:6]## [1] "Comedy, Drama, Romance" "Comedy, Crime, Mystery" "Comedy"
## [4] "Comedy, Musical" "Comedy, Drama, Music" "Drama"# Podemos detectar se o gênero Drama aparece na string
str_detect(
string = imdb$generos[1:6],
pattern = "Drama"
)## [1] TRUE FALSE FALSE FALSE TRUE TRUE# Aplicamos essa lógica dentro da função filter, para a coluna completa
imdb %>% filter(str_detect(generos, "Drama"))## # A tibble: 5,894 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0372122 Adam … 2005 2007-05-17 Comedy… 99 USA Engli… NA
## 3 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
## 4 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 5 tt0094006 Some … 1987 1988-01-13 Drama,… 95 USA Engli… NA
## 6 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
## 7 tt0035784 Dead … 1943 1943-04-12 Drama,… 64 USA Engli… NA
## 8 tt0025101 Fashi… 1934 1934-02-14 Comedy… 78 USA Engli… NA
## 9 tt0082009 Ameri… 1981 1981-02-13 Animat… 96 USA Engli… 1500000
## 10 tt0049474 The M… 1956 1956-05-08 Drama,… 153 USA Engli… 2670000
## # … with 5,884 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>Exercícios
Utilize a base imdb nos exercícios a seguir.
1. Crie um objeto chamado filmes_ingles apenas com filmes que sejam apenas no idioma inglês (English).
2. Crie um objeto chamado curtos_legais com filmes de 90 minutos ou menos de duração e nota no imdb maior do que 8.5.
3. Retorne tabelas (tibbles) apenas com:
a. filmes de ação anteriores a 1950;
b. filmes dirigidos por “Woody Allen” ou “Wes Anderson”;
c. filmes do “Steven Spielberg” ordenados de forma decrescente por ano, mostrando apenas as colunas
tituloeano;d. filmes que tenham “Action” ou “Comedy” entre os seus gêneros;
e. filmes que tenham “Action” e “Comedy” entre os seus gêneros e tenha
nota_imdbmaior que 8;f. filmes que não possuem informação tanto de receita quanto de orçamento (isto é, possuem
NAem ambas as colunas).
7.2.5 Modificando e criando novas colunas
Para modificar uma coluna existente ou criar uma nova coluna, utilizamos a função mutate(). O código abaixo divide os valores da coluna duração por 60, mudando a unidade de medida dessa variável de minutos para horas.
imdb %>% mutate(duracao = duracao/60)## # A tibble: 11,340 × 20
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 2.22 USA Engli… 20000000
## 2 tt0037931 Murde… 1945 1945-06-23 Comedy… 1.52 USA Engli… NA
## 3 tt0183505 Me, M… 2000 2000-09-08 Comedy 1.93 USA Engli… 51000000
## 4 tt0033945 Never… 1941 1947-05-02 Comedy… 1.18 USA Engli… NA
## 5 tt0372122 Adam … 2005 2007-05-17 Comedy… 1.65 USA Engli… NA
## 6 tt3703836 Henry… 2015 2016-01-08 Drama 1.45 USA Engli… NA
## 7 tt0093640 No Wa… 1987 1987-12-11 Action… 1.9 USA Engli… 15000000
## 8 tt0494652 Welco… 2008 2008-02-08 Comedy… 1.73 USA Engli… 35000000
## 9 tt0094006 Some … 1987 1988-01-13 Drama,… 1.58 USA Engli… NA
## 10 tt1142798 The F… 2008 2008-09-12 Drama 1.85 USA Engli… NA
## # … with 11,330 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>Também poderíamos ter criado essa variável em uma nova coluna. Repare que a nova coluna duracao_horas é colocada no final da tabela.
imdb %>% mutate(duracao_horas = duracao/60)## # A tibble: 11,340 × 21
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0037931 Murde… 1945 1945-06-23 Comedy… 91 USA Engli… NA
## 3 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
## 4 tt0033945 Never… 1941 1947-05-02 Comedy… 71 USA Engli… NA
## 5 tt0372122 Adam … 2005 2007-05-17 Comedy… 99 USA Engli… NA
## 6 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
## 7 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 8 tt0494652 Welco… 2008 2008-02-08 Comedy… 104 USA Engli… 35000000
## 9 tt0094006 Some … 1987 1988-01-13 Drama,… 95 USA Engli… NA
## 10 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
## # … with 11,330 more rows, and 12 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>, duracao_horas <dbl>Podemos fazer qualquer operação com uma ou mais colunas. A única regra é que o resultado da operação retorne um vetor com comprimento igual ao número de linhas da base (ou com comprimento 1 para distribuir um mesmo valor em todas as linhas). Você também pode criar/modificar quantas colunas quiser dentro de um mesmo mutate.
imdb %>%
mutate(lucro = receita - orcamento, pais = "Estados Unidos") %>%
select(titulo, lucro, pais)## # A tibble: 11,340 × 3
## titulo lucro pais
## <chr> <dbl> <chr>
## 1 Broadcast News 47331309 Estados Unidos
## 2 Murder, He Says NA Estados Unidos
## 3 Me, Myself & Irene 98270999 Estados Unidos
## 4 Never Give a Sucker an Even Break NA Estados Unidos
## 5 Adam & Steve NA Estados Unidos
## 6 Henry Gamble's Birthday Party NA Estados Unidos
## 7 No Way Out 20509515 Estados Unidos
## 8 Welcome Home, Roscoe Jenkins 8655418 Estados Unidos
## 9 Some Kind of Wonderful NA Estados Unidos
## 10 The Family That Preys NA Estados Unidos
## # … with 11,330 more rowsExercícios
Utilize a base imdb nos exercícios a seguir.
1. Crie uma coluna chamada prejuizo (orcamento - receita) e salve a nova tabela em um objeto chamado imdb_prejuizo. Em seguida, filtre apenas os filmes que deram prejuízo e ordene a tabela por ordem crescente de prejuízo.
2. Fazendo apenas uma chamada da função mutate(), crie as seguintes colunas novas na base imdb:
a.
lucro = receita - orcamentob.
lucro_medioc.
lucro_relativo = (lucro - lucro_medio)/lucro_mediod.
houve_lucro = ifelse(lucro > 0, "sim", "não")
3. Crie uma nova coluna que classifique o filme em "recente" (posterior a 2000) e "antigo" (de 2000 para trás).
7.2.6 Sumarizando a base
Sumarização é a técnica de se resumir um conjunto de dados utilizando alguma métrica de interesse. A média, a mediana, a variância, a frequência, a proporção, por exemplo, são tipos de sumarização que trazem diferentes informações sobre uma variável.
Para sumarizar uma coluna da base, utilizamos a função summarize(). O código abaixo resume a coluna orçamento pela sua média.
imdb %>% summarize(media_orcamento = mean(orcamento, na.rm = TRUE))## # A tibble: 1 × 1
## media_orcamento
## <dbl>
## 1 19030515.Repare que a saída da função continua sendo uma tibble.
Podemos calcular diversas sumarizações diferentes em um mesmo summarize. Cada sumarização será uma coluna da nova base.
imdb %>% summarise(
media_orcamento = mean(orcamento, na.rm = TRUE),
mediana_orcamento = median(orcamento, na.rm = TRUE),
variancia_orcamento = var(orcamento, na.rm = TRUE)
)## # A tibble: 1 × 3
## media_orcamento mediana_orcamento variancia_orcamento
## <dbl> <dbl> <dbl>
## 1 19030515. 6500000 1.05e15E também sumarizar diversas colunas.
imdb %>% summarize(
media_orcamento = mean(orcamento, na.rm = TRUE),
media_receita = mean(receita, na.rm = TRUE),
media_lucro = mean(receita - orcamento, na.rm = TRUE)
)## # A tibble: 1 × 3
## media_orcamento media_receita media_lucro
## <dbl> <dbl> <dbl>
## 1 19030515. 54682645. 50182761.Muitas vezes queremos sumarizar uma coluna agrupada pelas categorias de uma segunda coluna. Para isso, além do summarize, utilizamos também a função group_by().
O código a seguir calcula a receita média dos filmes para cada categoria da coluna “cor”.
imdb %>%
filter(!is.na(producao), !is.na(receita)) %>%
group_by(producao) %>%
summarise(receita_media = mean(receita, na.rm = TRUE)) ## # A tibble: 2,299 × 2
## producao receita_media
## <chr> <dbl>
## 1 .406 Production 10580
## 2 10 West Studios 814906
## 3 101st Street Films 181233
## 4 10th Hole Productions 191019
## 5 120dB Films 557263.
## 6 1492 Pictures 68581364.
## 7 1818 Productions 12232628
## 8 1821 Pictures 1537640.
## 9 19 Entertainment 4928883
## 10 1984 Private Defense Contractors 29430198.
## # … with 2,289 more rowsA única alteração que a função group_by() faz na base é a marcação de que a base está agrupada.
imdb %>% group_by(producao)## # A tibble: 11,340 × 20
## # Groups: producao [4,256]
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0037931 Murde… 1945 1945-06-23 Comedy… 91 USA Engli… NA
## 3 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
## 4 tt0033945 Never… 1941 1947-05-02 Comedy… 71 USA Engli… NA
## 5 tt0372122 Adam … 2005 2007-05-17 Comedy… 99 USA Engli… NA
## 6 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
## 7 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 8 tt0494652 Welco… 2008 2008-02-08 Comedy… 104 USA Engli… 35000000
## 9 tt0094006 Some … 1987 1988-01-13 Drama,… 95 USA Engli… NA
## 10 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
## # … with 11,330 more rows, and 11 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>Exercícios
Utilize a base imdb nos exercícios a seguir.
1. Calcule a duração média e mediana dos filmes da base.
2. Calcule o lucro médio dos filmes com duração maior que 2 horas (ou seja, 120 minutos).
3. Apresente na mesma tabela o lucro médio dos filmes com duracao menor que 120 minutos e o lucro médio dos filmes com duracao maior ou igual a 120 minutos.
4. Retorne tabelas (tibbles) apenas com:
a. a nota IMDB média dos filmes por ano de lançamento;
b. a receita média e mediana dos filmes por ano;
c. apenas o nome das pessoas que dirigiram mais de 10 filmes.
7.2.7 Juntando duas bases
Podemos juntar duas tabelas a partir de uma (coluna) chave utilizando a função left_join(). Como exempo, vamos inicialmente calcular o lucro médio dos filmes de cada direção e salvar no objeto tab_lucro_direcao.
tab_lucro_direcao <- imdb %>%
group_by(direcao) %>%
summarise(lucro_medio = mean(receita - orcamento, na.rm = TRUE))
tab_lucro_direcao## # A tibble: 5,140 × 2
## direcao lucro_medio
## <chr> <dbl>
## 1 A. Edward Sutherland NaN
## 2 A.J. Edwards NaN
## 3 A.T. White NaN
## 4 Aaron Blaise, Robert Walker 122397798
## 5 Aaron Hann, Mario Miscione NaN
## 6 Aaron Harvey -4349286.
## 7 Aaron Horvath, Peter Rida Michail 42090236
## 8 Aaron K. Carter NaN
## 9 Aaron Katz 13110
## 10 Aaron Kaufman NaN
## # … with 5,130 more rowsE se quisermos colocar essa informação na base original? Basta usar a função left_join() utilizando a coluna direcao como chave. Observe que a coluna lucro_medio aparece agora no fim da tabela.
imdb_com_lucro_medio <- left_join(imdb, tab_lucro_direcao, by = "direcao")
imdb_com_lucro_medio## # A tibble: 11,340 × 21
## id_filme titulo ano data_lancamento generos duracao pais idioma orcamento
## <chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 tt0092699 Broad… 1987 1988-04-01 Comedy… 133 USA Engli… 20000000
## 2 tt0037931 Murde… 1945 1945-06-23 Comedy… 91 USA Engli… NA
## 3 tt0183505 Me, M… 2000 2000-09-08 Comedy 116 USA Engli… 51000000
## 4 tt0033945 Never… 1941 1947-05-02 Comedy… 71 USA Engli… NA
## 5 tt0372122 Adam … 2005 2007-05-17 Comedy… 99 USA Engli… NA
## 6 tt3703836 Henry… 2015 2016-01-08 Drama 87 USA Engli… NA
## 7 tt0093640 No Wa… 1987 1987-12-11 Action… 114 USA Engli… 15000000
## 8 tt0494652 Welco… 2008 2008-02-08 Comedy… 104 USA Engli… 35000000
## 9 tt0094006 Some … 1987 1988-01-13 Drama,… 95 USA Engli… NA
## 10 tt1142798 The F… 2008 2008-09-12 Drama 111 USA Engli… NA
## # … with 11,330 more rows, and 12 more variables: receita <dbl>,
## # receita_eua <dbl>, nota_imdb <dbl>, num_avaliacoes <dbl>, direcao <chr>,
## # roteiro <chr>, producao <chr>, elenco <chr>, descricao <chr>,
## # num_criticas_publico <dbl>, num_criticas_critica <dbl>, lucro_medio <dbl>Na tabela imdb_com_lucro_medio, como na tabela imdb, cada linha continua a representar um filme diferente, mas agora temos também a informação do lucro médio da direção de cada filme.
A primeira linha, por exemplo, traz as informações do filme Avatar. O valor do lucro_medio nessa linha representa o lucro médio de todos os filmes do James Cameron, que é o diretor de Avatar. Com essa informação, podemos calcular o quanto o lucro do Avatar se afasta do lucro médio do James Cameron.
imdb_com_lucro_medio %>%
mutate(
lucro = receita - orcamento,
lucro_relativo = (lucro - lucro_medio)/lucro_medio,
lucro_relativo = scales::percent(lucro_relativo)
) %>%
select(titulo, direcao, lucro, lucro_medio, lucro_relativo)## # A tibble: 11,340 × 5
## titulo direcao lucro lucro_medio lucro_relativo
## <chr> <chr> <dbl> <dbl> <chr>
## 1 Broadcast News James L… 4.73e7 47749419. -0.87563%
## 2 Murder, He Says George … NA NaN <NA>
## 3 Me, Myself & Irene Bobby F… 9.83e7 74584082. 31.75868%
## 4 Never Give a Sucker an Even Break Edward … NA NaN <NA>
## 5 Adam & Steve Craig C… NA NaN <NA>
## 6 Henry Gamble's Birthday Party Stephen… NA NaN <NA>
## 7 No Way Out Roger D… 2.05e7 28936159. -29.12150%
## 8 Welcome Home, Roscoe Jenkins Malcolm… 8.66e6 35967552. -75.93548%
## 9 Some Kind of Wonderful Howard … NA 13381606. <NA>
## 10 The Family That Preys Tyler P… NA 33508412. <NA>
## # … with 11,330 more rowsObservamos então que o Avatar obteve um lucro aproximadamente 169% maior que a média dos filmes do James Cameron.
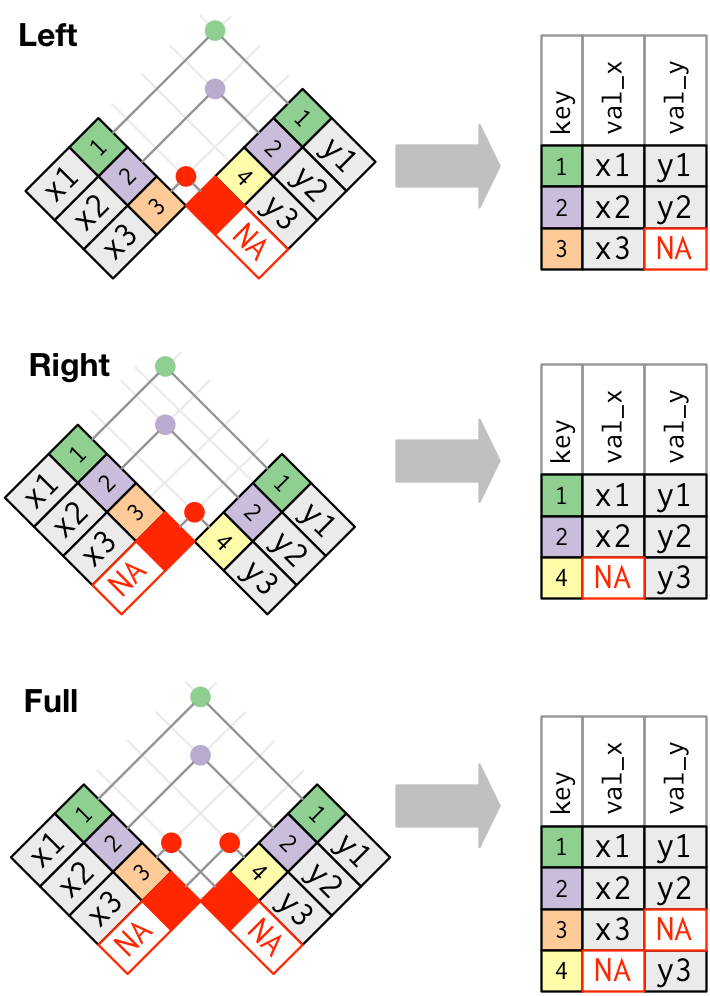
Além da função left_join(), também são muito utilizadas as funções right_join() e full_join().
right_join(): retorna todas as linhas da baseye todas as colunas das basesxey. Linhas deysem correspondentes emxreceberãoNAna nova base.full_join(): retorna todas as linhas e colunas dexey. Valores sem correspondência entre as bases receberãoNAna nova base.
A figura a seguir esquematiza as operações dessas funções:
Exercícios
1. Utilize a base imdb para resolver os itens a seguir.
a. Salve em um novo objeto uma tabela com a
nota média dos filmes de cada direção. Essa tabela
deve conter duas colunas (direcao e nota_imdb_media)
e cada linha deve ser uma direção diferente.
b. Use o left_join() para trazer a coluna
nota_imdb_media da tabela do item anterior
para a tabela imdb original.
7.2.8 dplyr 1.0
A versão 1.0 do pacote dplyr foi oficialmente lançada em junho de 2020 e contou com diversas novidades. Vamos falar das principais mudanças:
A nova função
across(), que facilita aplicar uma mesma operação em várias colunas.A repaginada função
rowwise(), para fazer operações por linha.Novas funcionalidades das funções
select()erename()e a nova funçãorelocate().
Para trabalhar essas funções, vamos utilizar a base casas do pacote dados. Para instalar esse pacote, rode os códigos abaixo:
install.packages("remotes")
remotes::install_github("cienciadedatos/dados")Para trazer os dados para o nosso environment, podemos rodar:
casas <- dados::casasA base casas possui dados de venda de casas na cidade de Ames, nos Estados Unidos. São 2930 linhas e 77 colunas, sendo que cada linha corresponde a uma casa vendida e cada coluna a uma característica da casa ou da venda. Essa versão é uma tradução da base original, que pode ser encontrada no pacote AmesHousing:
install.packages("AmesHousing")
data(ames_raw, package = "AmesHousing")A função across()
A função across() substitui a família de verbos _all(), _if e _at(). A ideia é facilitar a aplicação de uma operação a diversas colunas da base. Para sumarizar a base para mais de uma variável, antigamente poderíamos fazer:
casas %>%
group_by(geral_qualidade) %>%
summarise(
lote_area_media = mean(lote_area, na.rm = TRUE),
venda_valor_medio = mean(venda_valor, na.rm = TRUE)
)## # A tibble: 10 × 3
## geral_qualidade lote_area_media venda_valor_medio
## <chr> <dbl> <dbl>
## 1 abaixo da média 8464. 106485.
## 2 acima da média 9788. 162130.
## 3 boa 10309. 205026.
## 4 excelente 12777. 368337.
## 5 média 9996. 134753.
## 6 muito boa 10618. 270914.
## 7 Muito excelente 18071. 450217.
## 8 muito ruim 15214. 48725
## 9 regular 9439. 83186.
## 10 ruim 9326. 52325.Ou então utilizar a função summarise_at():
casas %>%
group_by(geral_qualidade) %>%
summarise_at(
.vars = vars(lote_area, venda_valor),
list(mean),
na.rm = TRUE
)## # A tibble: 10 × 3
## geral_qualidade lote_area venda_valor
## <chr> <dbl> <dbl>
## 1 abaixo da média 8464. 106485.
## 2 acima da média 9788. 162130.
## 3 boa 10309. 205026.
## 4 excelente 12777. 368337.
## 5 média 9996. 134753.
## 6 muito boa 10618. 270914.
## 7 Muito excelente 18071. 450217.
## 8 muito ruim 15214. 48725
## 9 regular 9439. 83186.
## 10 ruim 9326. 52325.Com a nova função across(), fazemos:
casas %>%
group_by(geral_qualidade) %>%
summarise(across(
.cols = c(lote_area, venda_valor),
.fns = mean,
na.rm = TRUE
))## # A tibble: 10 × 3
## geral_qualidade lote_area venda_valor
## <chr> <dbl> <dbl>
## 1 abaixo da média 8464. 106485.
## 2 acima da média 9788. 162130.
## 3 boa 10309. 205026.
## 4 excelente 12777. 368337.
## 5 média 9996. 134753.
## 6 muito boa 10618. 270914.
## 7 Muito excelente 18071. 450217.
## 8 muito ruim 15214. 48725
## 9 regular 9439. 83186.
## 10 ruim 9326. 52325.A sintaxe é parecida com a função summarise_at(), mas agora não precisamos mais usar a função vars() e nem usar list(nome_da_funcao)para definir a função aplicada nas colunas.
Usando across(), podemos facilmente aplicar uma função em todas as colunas da nossa base. Abaixo, calculamos o número de valores distintos para todas as variáveis da base casas. O padrão do parâmetro .cols é everything(), que representa “todas as colunas”.
casas %>%
summarise(across(.fns = n_distinct))## # A tibble: 1 × 82
## ordem pid moradia_classe moradia_zoneamento lote_fachada lote_area rua_tipo
## <int> <int> <int> <int> <int> <int> <int>
## 1 2930 2930 16 7 129 1960 2
## # … with 75 more variables: beco_tipo <int>, lote_formato <int>,
## # terreno_contorno <int>, utilidades <int>, lote_config <int>,
## # terreno_declive <int>, vizinhanca <int>, condicao_1 <int>,
## # condicao_2 <int>, moradia_tipo <int>, moradia_estilo <int>,
## # geral_qualidade <int>, geral_condicao <int>, construcao_ano <int>,
## # remodelacao_ano <int>, telhado_estilo <int>, telhado_material <int>,
## # exterior_cobertura_1 <int>, exterior_cobertura_2 <int>, …Para fazer essa mesma operação, antes utilizaríamos a função summarise_all().
casas %>%
summarise_all(.funs = ~n_distinct(.x))## # A tibble: 1 × 82
## ordem pid moradia_classe moradia_zoneamento lote_fachada lote_area rua_tipo
## <int> <int> <int> <int> <int> <int> <int>
## 1 2930 2930 16 7 129 1960 2
## # … with 75 more variables: beco_tipo <int>, lote_formato <int>,
## # terreno_contorno <int>, utilidades <int>, lote_config <int>,
## # terreno_declive <int>, vizinhanca <int>, condicao_1 <int>,
## # condicao_2 <int>, moradia_tipo <int>, moradia_estilo <int>,
## # geral_qualidade <int>, geral_condicao <int>, construcao_ano <int>,
## # remodelacao_ano <int>, telhado_estilo <int>, telhado_material <int>,
## # exterior_cobertura_1 <int>, exterior_cobertura_2 <int>, …Se quisermos selecionar as colunas a serem modificadas a partir de um teste lógico, utilizamos o ajudante where().
No exemplo abaixo, calculamos o número de valores distintos das colunas de categóricas.
casas %>%
summarise(across(where(is.character), n_distinct))## # A tibble: 1 × 47
## pid moradia_classe moradia_zoneamento rua_tipo beco_tipo lote_formato
## <int> <int> <int> <int> <int> <int>
## 1 2930 16 7 2 3 4
## # … with 41 more variables: terreno_contorno <int>, utilidades <int>,
## # lote_config <int>, terreno_declive <int>, vizinhanca <int>,
## # condicao_1 <int>, condicao_2 <int>, moradia_tipo <int>,
## # moradia_estilo <int>, geral_qualidade <int>, geral_condicao <int>,
## # telhado_estilo <int>, telhado_material <int>, exterior_cobertura_1 <int>,
## # exterior_cobertura_2 <int>, alvenaria_tipo <int>, exterior_qualidade <int>,
## # exterior_condicao <int>, fundacao_tipo <int>, porao_qualidade <int>, …Todas as colunas da base resultante eram colunas com classe character na base casas.
Anteriormente, utilizávamos a função summarise_if().
casas %>%
summarise_if(is.character, n_distinct)## # A tibble: 1 × 47
## pid moradia_classe moradia_zoneamento rua_tipo beco_tipo lote_formato
## <int> <int> <int> <int> <int> <int>
## 1 2930 16 7 2 3 4
## # … with 41 more variables: terreno_contorno <int>, utilidades <int>,
## # lote_config <int>, terreno_declive <int>, vizinhanca <int>,
## # condicao_1 <int>, condicao_2 <int>, moradia_tipo <int>,
## # moradia_estilo <int>, geral_qualidade <int>, geral_condicao <int>,
## # telhado_estilo <int>, telhado_material <int>, exterior_cobertura_1 <int>,
## # exterior_cobertura_2 <int>, alvenaria_tipo <int>, exterior_qualidade <int>,
## # exterior_condicao <int>, fundacao_tipo <int>, porao_qualidade <int>, …Com o across(), podemos combinar os efeitos de um summarise_if() e um summarise_at() em um único summarise(). A seguir, calculamos as áreas médias, garantindo que pegamos apenas variáveis numéricas.
casas %>%
summarise(across(where(is.numeric) & contains("_area"), mean, na.rm = TRUE))## # A tibble: 1 × 17
## lote_area alvenaria_area porao_area_com_aca… porao_area_com_… porao_area_sem_…
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 10148. 102. 443. 49.7 559.
## # … with 12 more variables: porao_area_total <dbl>, primeiro_andar_area <dbl>,
## # segundo_andar_area <dbl>, acabamento_baixa_qualidade_area <dbl>,
## # acima_solo_area <dbl>, garagem_area <dbl>, deck_madeira_area <dbl>,
## # varanda_aberta_area <dbl>, varanda_fechada_area <dbl>,
## # varanda_3ssn_area <dbl>, varanda_com_tela_area <dbl>, piscina_area <dbl>Além disso, com a função across(), podemos fazer sumarizações complexas que não seria possível utilizando apenas as funções summarise(), summarise_if() e summarise_at(). No exemplo a seguir, calculamos a média das áreas, o número de NAs de variáveis categóricas e o número de casas para cada tipo de fundação. Tudo em um mesmo summarise()!
casas %>%
group_by(fundacao_tipo) %>%
summarise(
across(where(is.numeric) & contains("area"), mean, na.rm = TRUE),
across(where(is.character), ~sum(is.na(.x))),
n_obs = n(),
) %>%
select(1:4, n_obs)## # A tibble: 6 × 5
## fundacao_tipo lote_area alvenaria_area porao_area_com_acabamento_1 n_obs
## <chr> <dbl> <dbl> <dbl> <int>
## 1 bloco de concreto 10616. 85.0 468. 1244
## 2 concreto derrramado 10054. 144. 506. 1310
## 3 laje 10250. 35.2 0 49
## 4 madeira 9838. 16 812. 5
## 5 pedra 8659. 0 43.9 11
## 6 tijolo e telha 8712. 10.2 151. 311Embora a nova sintaxe, usando across(), não seja muito diferente do que fazíamos antes, realizar sumarizações complexas não é a única vantagem desse novo framework.
O across() pode ser utilizado em todos os verbos do {dplyr} (com exceção do select() e rename(), já que ele não trás vantagens com relação ao que já podia ser feito) e isso unifica o modo de fazermos essas operações no dplyr. Em vez de termos uma família de funções para cada verbo, temos agora apenas o próprio verbo e a função across().
Vamos ver um exemplo para o mutate() e para o filter().
O código abaixo transforma todas as variáveis que possuem “area” no nome, passando os valores de pés quadrados para metros quadrados.
casas %>%
mutate(across(
contains("area"),
~ .x / 10.764
))Já o código a seguir filtra apenas as casas que possuem varanda aberta, cerca e lareira (o NA nessa base significa que a casa não possui tal característica).
casas %>%
filter(across(
c(varanda_aberta_area, cerca_qualidade, lareira_qualidade),
~!is.na(.x)
)) Não precisamos do across() na hora de selecionar colunas. A função select() já usa naturalmente o mecanismo de seleção de colunas que o across() proporciona.
casas %>%
select(where(is.numeric))## # A tibble: 2,930 × 35
## ordem lote_fachada lote_area construcao_ano remodelacao_ano alvenaria_area
## <int> <int> <int> <int> <int> <int>
## 1 1 141 31770 1960 1960 112
## 2 2 80 11622 1961 1961 0
## 3 3 81 14267 1958 1958 108
## 4 4 93 11160 1968 1968 0
## 5 5 74 13830 1997 1998 0
## 6 6 78 9978 1998 1998 20
## 7 7 41 4920 2001 2001 0
## 8 8 43 5005 1992 1992 0
## 9 9 39 5389 1995 1996 0
## 10 10 60 7500 1999 1999 0
## # … with 2,920 more rows, and 29 more variables:
## # porao_area_com_acabamento_1 <int>, porao_area_com_acabamento_2 <int>,
## # porao_area_sem_acabamento <int>, porao_area_total <int>,
## # porao_num_banheiros <int>, porao_num_banheiros_lavabos <int>,
## # primeiro_andar_area <int>, segundo_andar_area <int>,
## # acabamento_baixa_qualidade_area <int>, acima_solo_area <int>,
## # acima_solo_num_banheiros <int>, acima_solo_num_lavabos <int>, …O mesmo vale para o rename(). Se quisermos renomer várias colunas, a partir de uma função, utilizamos o rename_with().
casas %>%
rename_with(toupper, contains("venda"))## # A tibble: 2,930 × 82
## ordem pid moradia_classe moradia_zoneame… lote_fachada lote_area rua_tipo
## <int> <chr> <chr> <chr> <int> <int> <chr>
## 1 1 052630… 020 Residencial bai… 141 31770 pavimen…
## 2 2 052635… 020 Residencial alt… 80 11622 pavimen…
## 3 3 052635… 020 Residencial bai… 81 14267 pavimen…
## 4 4 052635… 020 Residencial bai… 93 11160 pavimen…
## 5 5 052710… 060 Residencial bai… 74 13830 pavimen…
## 6 6 052710… 060 Residencial bai… 78 9978 pavimen…
## 7 7 052712… desenvolvimen… Residencial bai… 41 4920 pavimen…
## 8 8 052714… desenvolvimen… Residencial bai… 43 5005 pavimen…
## 9 9 052714… desenvolvimen… Residencial bai… 39 5389 pavimen…
## 10 10 052716… 060 Residencial bai… 60 7500 pavimen…
## # … with 2,920 more rows, and 75 more variables: beco_tipo <chr>,
## # lote_formato <chr>, terreno_contorno <chr>, utilidades <chr>,
## # lote_config <chr>, terreno_declive <chr>, vizinhanca <chr>,
## # condicao_1 <chr>, condicao_2 <chr>, moradia_tipo <chr>,
## # moradia_estilo <chr>, geral_qualidade <chr>, geral_condicao <chr>,
## # construcao_ano <int>, remodelacao_ano <int>, telhado_estilo <chr>,
## # telhado_material <chr>, exterior_cobertura_1 <chr>, …A função relocate()
O {dplyr} possui agora uma função própria para reorganizar colunas: relocate(). Por padrão, ela coloca uma ou mais colunas no começo da base.
casas %>%
relocate(venda_valor, venda_tipo)## # A tibble: 2,930 × 82
## venda_valor venda_tipo ordem pid moradia_classe moradia_zoneame…
## <int> <chr> <int> <chr> <chr> <chr>
## 1 215000 "WD " 1 0526301100 020 Residencial bai…
## 2 105000 "WD " 2 0526350040 020 Residencial alt…
## 3 172000 "WD " 3 0526351010 020 Residencial bai…
## 4 244000 "WD " 4 0526353030 020 Residencial bai…
## 5 189900 "WD " 5 0527105010 060 Residencial bai…
## 6 195500 "WD " 6 0527105030 060 Residencial bai…
## 7 213500 "WD " 7 0527127150 desenvolvimento de … Residencial bai…
## 8 191500 "WD " 8 0527145080 desenvolvimento de … Residencial bai…
## 9 236500 "WD " 9 0527146030 desenvolvimento de … Residencial bai…
## 10 189000 "WD " 10 0527162130 060 Residencial bai…
## # … with 2,920 more rows, and 76 more variables: lote_fachada <int>,
## # lote_area <int>, rua_tipo <chr>, beco_tipo <chr>, lote_formato <chr>,
## # terreno_contorno <chr>, utilidades <chr>, lote_config <chr>,
## # terreno_declive <chr>, vizinhanca <chr>, condicao_1 <chr>,
## # condicao_2 <chr>, moradia_tipo <chr>, moradia_estilo <chr>,
## # geral_qualidade <chr>, geral_condicao <chr>, construcao_ano <int>,
## # remodelacao_ano <int>, telhado_estilo <chr>, telhado_material <chr>, …Podemos usar os argumentos .after e .before para fazer mudanças mais complexas.
O código baixo coloca a coluna venda_ano depois da coluna construcao_ano.
casas %>%
relocate(venda_ano, .after = construcao_ano)O código baixo coloca a coluna venda_ano antes da coluna construcao_ano.
casas %>%
relocate(venda_ano, .before = construcao_ano)A função rowwise()
Por fim, vamos discutir operações feitas por linha. Tome como exemplo a tabela abaixo. Ela apresenta as notas de alunos em quatro provas.
tab_notas <- tibble(
student_id = 1:5,
prova1 = sample(0:10, 5),
prova2 = sample(0:10, 5),
prova3 = sample(0:10, 5),
prova4 = sample(0:10, 5)
)
tab_notas## # A tibble: 5 × 5
## student_id prova1 prova2 prova3 prova4
## <int> <int> <int> <int> <int>
## 1 1 8 1 6 3
## 2 2 2 3 7 0
## 3 3 9 2 0 1
## 4 4 10 7 10 6
## 5 5 0 5 9 2Se quisermos gerar uma coluna com a nota média de cada aluno nas quatro provas, não poderíamos usar o mutate() diretamente.
tab_notas %>% mutate(media = mean(c(prova1, prova2, prova3, prova4)))## # A tibble: 5 × 6
## student_id prova1 prova2 prova3 prova4 media
## <int> <int> <int> <int> <int> <dbl>
## 1 1 8 1 6 3 4.55
## 2 2 2 3 7 0 4.55
## 3 3 9 2 0 1 4.55
## 4 4 10 7 10 6 4.55
## 5 5 0 5 9 2 4.55Neste caso, todas as colunas estão sendo empilhadas e gerando uma única média, passada a todas as linhas da coluna media.
Para fazermos a conta para cada aluno, podemos agrupar por aluno. Agora sim a média é calculada apenas nas notas de cada estudante.
tab_notas %>%
group_by(student_id) %>%
mutate(media = mean(c(prova1, prova2, prova3, prova4)))## # A tibble: 5 × 6
## # Groups: student_id [5]
## student_id prova1 prova2 prova3 prova4 media
## <int> <int> <int> <int> <int> <dbl>
## 1 1 8 1 6 3 4.5
## 2 2 2 3 7 0 3
## 3 3 9 2 0 1 3
## 4 4 10 7 10 6 8.25
## 5 5 0 5 9 2 4Também podemos nos aproveitar da sintaxe do across() neste caso. Para isso, precisamos substutir a função c() pela função c_across().
tab_notas %>%
group_by(student_id) %>%
mutate(media = mean(c_across(starts_with("prova"))))## # A tibble: 5 × 6
## # Groups: student_id [5]
## student_id prova1 prova2 prova3 prova4 media
## <int> <int> <int> <int> <int> <dbl>
## 1 1 8 1 6 3 4.5
## 2 2 2 3 7 0 3
## 3 3 9 2 0 1 3
## 4 4 10 7 10 6 8.25
## 5 5 0 5 9 2 4Equivalentemente ao group_by(), neste caso, podemos usar a função rowwise().
tab_notas %>%
rowwise(student_id) %>%
mutate(media = mean(c_across(starts_with("prova"))))## # A tibble: 5 × 6
## # Rowwise: student_id
## student_id prova1 prova2 prova3 prova4 media
## <int> <int> <int> <int> <int> <dbl>
## 1 1 8 1 6 3 4.5
## 2 2 2 3 7 0 3
## 3 3 9 2 0 1 3
## 4 4 10 7 10 6 8.25
## 5 5 0 5 9 2 4Ela é muito útil quando queremos fazer operação por linhas, mas não temos uma coluna de identificação. Por padrão, se não indicarmos nenhuma coluna, cada linha será um “grupo”.
tab_notas %>%
rowwise() %>%
mutate(media = mean(c_across(starts_with("prova"))))## # A tibble: 5 × 6
## # Rowwise:
## student_id prova1 prova2 prova3 prova4 media
## <int> <int> <int> <int> <int> <dbl>
## 1 1 8 1 6 3 4.5
## 2 2 2 3 7 0 3
## 3 3 9 2 0 1 3
## 4 4 10 7 10 6 8.25
## 5 5 0 5 9 2 4Veja que student_id não é passada para a função rowwise(). Não precisaríamos dessa coluna na base para reproduzir a geração da columa media neste caso.
Exercícios
A base casas abaixo pode ser encontrada a partir do código abaixo:
remotes::install_github("cienciadedatos/dados")
dados::casas1. Reescreva os códigos abaixo utilizando as funções across() e where().
a.
casas %>%
group_by(geral_qualidade) %>%
summarise(
acima_solo_area_media = mean(acima_solo_area, na.rm = TRUE),
garagem_area_media = mean(garagem_area, na.rm = TRUE),
valor_venda_medio = mean(venda_valor, na.rm = TRUE)
)b.
casas %>%
filter_at(
vars(porao_qualidade, varanda_fechada_area, cerca_qualidade),
~!is.na(.x)
)c.
casas %>%
mutate_if(is.character, ~tidyr::replace_na(.x, replace = "Não possui"))2. Utilizando a base casas, resolva os itens a seguir.
a. Usando o
case_when()crie um código para categorizar a variável venda_valor da seguinte maneira:- barata: $0 a $129.500
- preço mediano: $129.500 a $180.796
- cara: $ 180.796 a $213.500
- muito cara: maior que $213.500
- barata: $0 a $129.500
- b. Utilize o código feito na letra (a) para agrupar a base
casaspela variável venda_valor categorizada e calcular todas as áreas médias para cada uma dessas categorias.
3. Escreva um código que receba a base casas e retorne uma tabela com apenas
a. as colunas referentes à garagem da casa.
b. as colunas referentes a variáveis de qualidade.
c. colunas numéricas que representam áreas da casa e do terreno.
d. colunas numéricas.
e. colunas referentes à piscina, porão e o valor de venda.
4. Usando a função rename_with(), troque todos os "_" dos nomes das colunas por um espaço " ".
5. Escreva um código para colocar todas as colunas relativas a venda no começo da base casas.
6. 5. Escreva um código para colocar todas as colunas numéricas da base casas no começo da tabela e todas as colunas categóricas no final.